Проверка гипотез относительно коэффициентов линейного уравнения регрессии
Для определения качества модели уравнения регрессии осуществляется процедура проверки гипотез. Статистическая гипотеза - это гипотеза о виде неизвестного распределения, или о параметрах известных распределений. Основной принцип проверки статистических гипотез: если наблюдаемое значение принадлежит критической области - гипотезу отвергают; если наблюдаемое значение принадлежит области допустимых значений - гипотезу принимают. Правило принятия решения для проверки статистических гипотез - это модель расчета значений выборочных статистических показателей, на основании которых принимается или отвергается нулевая гипотеза. Процедура проверки гипотезы следующая: необходимо сформулировать нулевую и альтернативную гипотезы; определить уровень значимости; найти наблюдаемое значение, используя формулу стандартизированного критерия; по таблице выяснить критическое значение в соответствии с уровнем значимости и размером выборки, если это необходимо; сравнить критическое значение с наблюдаемым, тем самым использовать правило принятия решения. Цель работы - овладеть навыками определения параметров линейной регрессии и корреляции с использованием формул и табличного процессора MS Excel, ознакомиться с методикой расчета показателей парной нелинейной регрессии и корреляции, овладеть приемами построения нелинейных регрессионных моделей с помощью MS Exсel, овладеть методикой построения линейных моделей множественной регрессии, оценки их существенности и значимости, расчетом показателей множественной регрессии и корреляции. Проверка гипотез относительно коэффициентов линейного уравнения регрессии. Статистическая гипотеза - это гипотеза о виде неизвестного распределения, или о параметрах известных распределений. Нулевой гипотезой (H0) называют выдвинутую гипотезу. Конкурирующей (альтернативной)(H1) называют гипотезу, которая противоречит нулевой. Гипотезу, содержащую только одно предположение, называют простой. Например, математическое ожидание нормально распределенной величины равно 5. Гипотеза, которая состоит из двух или нескольких простых гипотез, называют сложной. Например, математическое ожидание нормально распределенной величины больше 5. Так как проверку производят методами статистики, ее называют статистической. Ошибка первого рода состоит в том, что будет отвергнута правильная гипотеза. Ошибка второго рода состоит в том, что будет принята неправильная гипотеза. Вероятность совершить ошибку первого рода принято обозначать α , ее называют уровень значимости. Наиболее уровень значимости принимают равным 0,05 или 0,01. Статистическим критерием называют случайную величину, которая служит для проверки нулевой гипотезы. Наблюдаемым значением называют значения критерия, вычисленного по выборкам. Критической областью называют совокупность значений критерия, при которых нулевая гипотеза отвергается. Областью принятия гипотезы (область допустимых значений) называют совокупность значений критерия, при которых гипотезу принимают. Основной принцип проверки статистических гипотез: если наблюдаемое значение принадлежит критической области - гипотезу отвергают; если наблюдаемое значение принадлежит области допустимых значений - гипотезу принимают. Критические точки - это точки, отделяющие критическую область от области принятия гипотезы. Различают одностороннюю (лево- и правостороннюю) и двустороннюю критические области. Правило принятия решения для проверки статистических гипотез - это модель расчета значений выборочных статистических показателей, на основании которых принимается или отвергается нулевая гипотеза. Процедура проверки гипотезы следующая: необходимо сформулировать нулевую и альтернативную гипотезы; определить уровень значимости; найти наблюдаемое значение, используя формулу стандартизированного критерия; по таблице выяснить критическое значение в соответствии с уровнем значимости и размером выборки, если это необходимо; сравнить критическое значение с наблюдаемым, тем самым использовать правило принятия решения. При проверке качества модели в первую очередь стоит обращать внимание на то, соответствует ли она логике экономического процесса, т.е. мы должны смотреть, реалистичны ли знаки коэффициентов перед независимыми переменными и реалистична ли их величина.статистика:статистика соизмеряет значение коэффициента с его стандартной ошибкой. Фактически же мы проверяем гипотезу о том, равен нулю коэффициент при рассматриваемой переменной или нет. Т.е:: коэффициент=0. Если эта гипотеза верна, то коэффициент не значим.: коэффициент не равен 0. Если эта гипотеза верна, то коэффициент значим. Выяснить, отвергается нулевая гипотеза или нет, можно 2 способами: 1. Метод критических значений (по таблицам): a) Находим фактическое значение t:) Определяем число степеней свободы m=n-k n - число наблюдений- число оцененных параметров) Выбираем уровень значимости (т.е. вероятность ошибки): 1% или 5%.) Находим критическое значение по таблице: в таблице выбираем клетку в строке, соответствующей числу степеней свободы и в столбце, соответствующем выбранному уровню значимости.) Сравниваем фактическое значение с табличным: Если t > t , то коэффициент значим на выбранном уровне значимости (лучше сначала на 1% проверить). Т.е. нулевая гипотеза отвергается. Если t < t , то коэффициент не значим. Нулевая гипотеза не отвергается.статистика:статистика представляет собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную) к остаточной сумме квадратов (в расчете на одну степень свободы). Фактически проверяем гипотезу: Но: все коэффициенты при независимых переменных равны нулю На: хотя бы один из них нулю не равен. Выяснить, отвергается нулевая гипотеза или нет, можно 2 способами: 1. По таблицам: a) Рассчитываем фактическое по формуле: F(k-1,n-k)= , где k - число объясняющих переменных.) Находим табличное: · Выбираем уровень значимости α (1% или 5%) · Вычисляем число степеней свободы: 1 и (n-2). · По таблицам F-распределения Фишера определяем критическое значение Fα, 1, n-2 (всегда одностороннее)) Если Fстатистика(фактическое) > Fα , 1, n-2, то уравнение в целом является значимым при выбранном уровне значимости α . d) В противном случае уравнение в целом незначимо (на данном уровне α). Задание 1. . Для характеристики зависимости у от х рассчитать параметры следующих уравнений регрессии: а) линейной; б) параболической в) степенной; . Рассчитать коэффициент корреляции или индекс корреляции и коэффициент детерминации по каждой модели. . Оценить каждую модель через среднюю ошибку аппроксиминации Ā и F-критерий Фишера.
линейный регрессия корреляция детерминация Решение: 1 Расчет параметров линейной регрессии. Парная линейная регрессия - уравнение вида Параметры уравнения a и b, находят посредством Метода Наименьших Квадратов. Рассчитаем вспомогательные параметры в таблице:
По найденным значениям вычислим параметр b (коэффициент регрессии):
Рассчитаем значение а: Тогда уравнение регрессии запишется следующим образом:
. Для оценки тесноты связи в эконометрике используется коэффициент корреляции (r).
В нашем случае значение коэффициента корреляции 0,85 говорит о сильной связи между х и у, т.е. связь между индексом человеческого развития и душевым доходом очень сильная. Рассчитаем коэффициент детерминации R2. R2=(0.85)2= 0.72. Таким образом, вариация величины доли душевого дохода на 72% зависит от вариации индекса человеческого развития, а на остальные (100%-72%) 28% − от вариации факторов, не включенных в модель. . Расчет средней ошибки аппроксимации. Определим среднюю ошибку аппроксимации по формуле:
Используем данные вспомогательной таблицы:
Тогда средняя ошибка аппроксимации равна
Практически полагают, что значение средней ошибки аппроксимации не должно превышать 8-15%, для грубого приближения регрессии к реальной зависимости. В нашем случае средняя ошибка аппроксимации приблизительно равна указанному значению, поэтому можно говорить о том, что реальная зависимость существует. . Оценка значимости уравнения регрессии в целом даётся при помощи F-критерия Фишера. При этом выдвигается нулевая гипотеза (Н0), что b=0, и, следовательно, фактор х не оказывает влияния на фактор у. Но перед этим следует произвести анализ дисперсии. Рассчитаем Dфакт и Dостат:
Сопоставляя факторную и остаточную дисперсии получаем F-критерий (величину F-отношения): Вычислим критическое значение критерия Фишера на уровне значимости a=0,05 и числе степеней свободы факторной суммы k1 и числе степеней свободы остаточной суммы k2 с помощью статистической функции FPACПОБР: Fкр(a=0,05, k1 =k-1; k2 =n-k)=5,32, где n=11 - объем выборки; k=2 - количество коэффициентов в уравнении. Так как F=23> Fкр (a=0,05, k1 = 1; k2 =9)=5, то нулевая гипотеза Н0 отвергается и утверждается, что фактор х оказывает влияние на фактор у, уравнение регрессии признаётся значимым (модель достоверна). 2 Расчет параметров параболической регрессии Спецификация модели зависимости у от х с помощью параболической
функции Приведем эту функцию к линейному виду. Для этого заменив переменные х=х1, х2=х2, получим двухфакторное уравнение линейной регрессии:
Исходные и расчетные данные для оценки коэффициентов функции представлены в таблице:
|

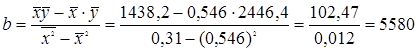
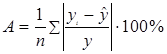
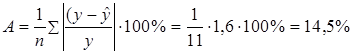
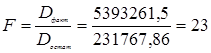 . Если гипотеза Н0 справедлива,
то факторная и остаточная дисперсии не отличаются друг от друга. Для того,
чтобы опровергнуть гипотезу Н0, необходимо полученное F-отношение сравнить с табличным Fкр,
которое берётся из таблиц Фишера - Снедекора (при разных уровнях значимости)
или определяется по функции Excel
FPACПОБР.
. Если гипотеза Н0 справедлива,
то факторная и остаточная дисперсии не отличаются друг от друга. Для того,
чтобы опровергнуть гипотезу Н0, необходимо полученное F-отношение сравнить с табличным Fкр,
которое берётся из таблиц Фишера - Снедекора (при разных уровнях значимости)
или определяется по функции Excel
FPACПОБР.